How much does knowing how fast a person responded improve predictions of whether they answered correctly? We fit Rasch IRT to binary accuracy data from IRW datasets with response times, then quantify the gain from adding within-item-centered log(RT) using the InterModel Vigorish (IMV). Motivated by Domingue et al. (2022).
Published
June 23, 2026
Overview
IRT models predict binary accuracy from a latent ability estimate — but they ignore when a person responded. Response time (RT) carries its own signal about item-person fit: very fast incorrect responses may reflect guessing, while slow correct responses may reflect effortful retrieval. The question is whether RT adds predictive value over and above the IRT probability.
We answer this using the InterModel Vigorish [IMV; Domingue et al. (2022)], a log-score measure of how much one model’s predictions improve on another’s. For each IRW dataset with RT and binary accuracy, we compare three nested models:
M0: resp ~ (1|item) + (1|id) — a random-item Rasch model (De Boeck et al. 2011) with crossed random effects for item difficulty and person ability, no RT
rt_cwi = log(rt) − mean_item(log(rt)) centers RT within items, isolating the micro-speed–accuracy tradeoff: is this person faster or slower than average on this item, and does that predict correctness? The random effects for item and person replace a separately-fitted Rasch model, estimating item difficulty and person ability jointly with the RT effect.
spl1–spl4 are the four columns of a B-spline basis (bs(rt_cwi, df=4)) computed from rt_cwi on the full dataset and stored as pre-computed columns. Precomputing the basis (rather than evaluating bs() inline) ensures that imv()’s internal model updates operate on the same feature matrix.
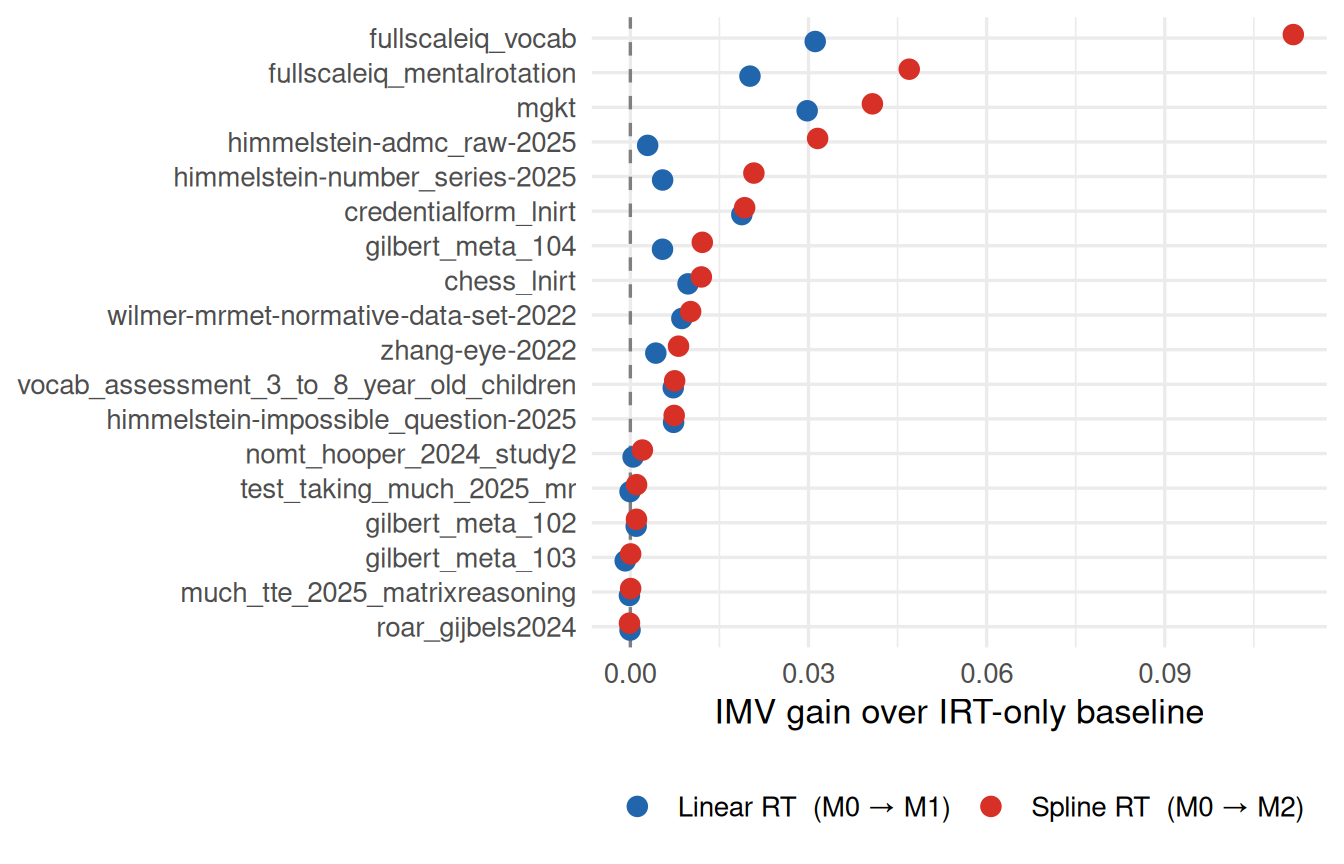
Figure 1: IMV gain from adding RT to IRT predictions. Blue = linear RT (M0→M1); red = spline RT (M0→M2). Positive values indicate RT improves predictions. Datasets ordered by spline IMV.
Across 18 datasets, the median IMV gain from adding linear RT is 0.0054 (78% of datasets positive); the spline gain is 0.0091 (94% positive).
Discussion
RT adds modest but consistent predictive value. Positive IMV for both linear and spline RT indicates that response time generally adds value in prediction of accuracy.
In some cases, the gains come from adding RT nonlinearly. RT can be a highly nonlinear predictor of response time. Indeed, the relationship between response time and accuracy may even be nonmonotonic.
De Boeck, Paul, Marjan Bakker, Robert Zwitser, et al. 2011. “The Estimation of Item Response Models with the Lmer Function from the Lme4 Package in R.”Journal of Statistical Software 39 (12): 1–28. https://doi.org/10.18637/jss.v039.i12.
Domingue, Benjamin W., Klint Kanopka, Ben Stenhaug, et al. 2022. “Speed–Accuracy Trade-Off? Not so Fast: Marginal Changes in Speed Have Inconsistent Relationships with Accuracy in Real Data.”Journal of Educational and Behavioral Statistics 47 (5): 576–602. https://doi.org/10.3102/10769986221099115.