# pip install --upgrade setuptools
# pip install "git+https://github.com/itemresponsewarehouse/Python-pkg.git"
# pip install mirt girth scipy matplotlibEstimating IRT Models in Python
A step-by-step introduction to importing IRW data in Python and fitting standard IRT models (1PL, 2PL, 3PL, and graded response) using the mirt and girth packages.
This vignette walks through a complete Python workflow for working with IRW data: fetching a dataset, preparing it for IRT estimation, fitting the 1PL (Rasch), 2PL, and 3PL models for dichotomous responses, and the graded response model (GRM) for polytomous data. We use the irw package for data access, mirt for dichotomous estimation, and girth for the GRM.
Setup
Install required packages
Load libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import irw
from mirt import fit_mirt
from girth import grm_mml, tag_missing_data, INVALID_RESPONSEPart 1: Dichotomous IRT (1PL, 2PL, 3PL)
Fetch a dataset
We start with 4thgrade_math_sirt, a dichotomous cognitive dataset from the IRW containing math item responses from fourth-grade students. On first use, irw.fetch() will open a browser window prompting you to authenticate with your Redivis account.
df = irw.fetch("4thgrade_math_sirt")
print(df.head())
print(f"\nShape: {df.shape}")
print(f"Columns: {df.columns.tolist()}")Warning: Setting the REDIVIS_API_TOKEN for interactive sessions is deprecated and highly discouraged.
Please delete the token on Redivis and remove it from your code, and follow the authentication prompts here instead.
This environment variable should only ever be set in a non-interactive environment, such as in an automated script or service.
Warning: Setting the REDIVIS_API_TOKEN for interactive sessions is deprecated and highly discouraged.
Please delete the token on Redivis and remove it from your code, and follow the authentication prompts here instead.
This environment variable should only ever be set in a non-interactive environment, such as in an automated script or service.
Warning: Setting the REDIVIS_API_TOKEN for interactive sessions is deprecated and highly discouraged.
Please delete the token on Redivis and remove it from your code, and follow the authentication prompts here instead.
This environment variable should only ever be set in a non-interactive environment, such as in an automated script or service.
item id resp testlet domain subdomain
0 MA1 125 0 MA arithmetic addition
1 MA1 653 0 MA arithmetic addition
2 MA1 483 0 MA arithmetic addition
3 MA1 609 0 MA arithmetic addition
4 MA1 412 0 MA arithmetic addition
Shape: (19920, 6)
Columns: ['item', 'id', 'resp', 'testlet', 'domain', 'subdomain']IRW data is in long format: one row per person–item response. The key columns are:
id— respondent identifieritem— item identifierresp— response value (0/1 for dichotomous items)
Prepare the response matrix
mirt expects a wide integer array of shape (n_persons, n_items) with missing responses coded as -1. We use irw.long2resp() to reshape from long to wide, then convert.
# Reshape from long to wide (persons × items)
resp_wide = irw.long2resp(df)
resp_wide = resp_wide.drop(columns="id", errors="ignore")
# Convert to numeric; encode missing as -1
resp_arr = resp_wide.apply(pd.to_numeric, errors="coerce").to_numpy(dtype=float, na_value=np.nan)
n_persons, n_items = resp_arr.shape
print(f"Persons: {n_persons}, Items: {n_items}")
print(f"Overall proportion correct: {np.nanmean(resp_arr):.3f}")
resp_matrix = np.where(np.isnan(resp_arr), -1, resp_arr).astype(int)Persons: 664, Items: 30
Overall proportion correct: 0.510Fit the 1PL (Rasch) model
The 1PL constrains all items to share a common discrimination, estimating only item difficulties (the b parameters). fit_mirt uses marginal maximum likelihood via expectation-maximisation (EM).
item_names = resp_wide.columns.tolist()
fit_1pl = fit_mirt(resp_matrix, model="1PL", item_names=item_names)
print(fit_1pl.summary())================================================================================
IRT Model Results
================================================================================
Model: 1PL Log-Likelihood: -12319.6172
No. Items: 30 AIC: 24759.2345
No. Factors: 1 BIC: 25029.1314
No. Persons: 664 No. Parameters: 60
Converged: True Iterations: 17
--------------------------------------------------------------------------------
discrimination:
Item Estimate Std.Err z-value P>|z| [95% CI]
--------------------------------------------------------------------------------
MA1 1.0000 0.0000 nan nan nan nan
MA2 1.0000 0.0000 nan nan nan nan
MA3 1.0000 0.0000 nan nan nan nan
MA4 1.0000 0.0000 nan nan nan nan
MB1 1.0000 0.0000 nan nan nan nan
MB2 1.0000 0.0000 nan nan nan nan
MB3 1.0000 0.0000 nan nan nan nan
MB4 1.0000 0.0000 nan nan nan nan
MC1 1.0000 0.0000 nan nan nan nan
MC2 1.0000 0.0000 nan nan nan nan
MC3 1.0000 0.0000 nan nan nan nan
MC4 1.0000 0.0000 nan nan nan nan
MD1 1.0000 0.0000 nan nan nan nan
MD2 1.0000 0.0000 nan nan nan nan
MD3 1.0000 0.0000 nan nan nan nan
MD4 1.0000 0.0000 nan nan nan nan
ME1 1.0000 0.0000 nan nan nan nan
ME2 1.0000 0.0000 nan nan nan nan
MF1 1.0000 0.0000 nan nan nan nan
MG1 1.0000 0.0000 nan nan nan nan
MG2 1.0000 0.0000 nan nan nan nan
MG3 1.0000 0.0000 nan nan nan nan
MG4 1.0000 0.0000 nan nan nan nan
MH1 1.0000 0.0000 nan nan nan nan
MH2 1.0000 0.0000 nan nan nan nan
MH3 1.0000 0.0000 nan nan nan nan
MH4 1.0000 0.0000 nan nan nan nan
MI1 1.0000 0.0000 nan nan nan nan
MI2 1.0000 0.0000 nan nan nan nan
MI3 1.0000 0.0000 nan nan nan nan
difficulty:
Item Estimate Std.Err z-value P>|z| [95% CI]
--------------------------------------------------------------------------------
MA1 -2.3541 0.1277 -18.441 0.0000 -2.6043 -2.1039
MA2 -0.2902 0.0851 -3.410 0.0006 -0.4571 -0.1234
MA3 -0.1176 0.0846 -1.390 0.1646 -0.2834 0.0482
MA4 0.4653 0.0858 5.421 0.0000 0.2971 0.6336
MB1 -0.6463 0.0874 -7.391 0.0000 -0.8177 -0.4749
MB2 -0.5553 0.0867 -6.407 0.0000 -0.7252 -0.3855
MB3 0.7367 0.0880 8.371 0.0000 0.5642 0.9092
MB4 0.7213 0.0879 8.209 0.0000 0.5491 0.8935
MC1 -1.3914 0.0984 -14.147 0.0000 -1.5842 -1.1987
MC2 0.0967 0.0845 1.144 0.2526 -0.0690 0.2623
MC3 -0.7940 0.0889 -8.928 0.0000 -0.9683 -0.6197
MC4 -0.2541 0.0850 -2.990 0.0028 -0.4206 -0.0875
MD1 -0.8982 0.0902 -9.960 0.0000 -1.0749 -0.7215
MD2 -1.2873 0.0963 -13.368 0.0000 -1.4760 -1.0985
MD3 -0.4955 0.0862 -5.746 0.0000 -0.6646 -0.3265
MD4 -0.5030 0.0863 -5.829 0.0000 -0.6721 -0.3339
ME1 -0.9805 0.0913 -10.742 0.0000 -1.1594 -0.8016
ME2 0.5171 0.0862 6.001 0.0000 0.3482 0.6860
MF1 -0.3193 0.0852 -3.746 0.0002 -0.4863 -0.1522
MG1 0.3847 0.0854 4.506 0.0000 0.2174 0.5521
MG2 0.7756 0.0884 8.773 0.0000 0.6024 0.9489
MG3 0.3121 0.0851 3.669 0.0002 0.1454 0.4788
MG4 0.4653 0.0858 5.421 0.0000 0.2971 0.6336
MH1 0.0182 0.0845 0.215 0.8298 -0.1474 0.1837
MH2 0.6295 0.0870 7.234 0.0000 0.4590 0.8001
MH3 0.3629 0.0853 4.255 0.0000 0.1957 0.5300
MH4 0.8228 0.0889 9.253 0.0000 0.6485 0.9971
MI1 0.8387 0.0891 9.412 0.0000 0.6640 1.0133
MI2 0.1825 0.0847 2.156 0.0311 0.0166 0.3485
MI3 1.6350 0.1035 15.794 0.0000 1.4321 1.8379
================================================================================Fit the 2PL model
The 2PL additionally estimates a discrimination parameter (a) for each item, allowing items to differ in how sharply they separate high- and low-ability respondents.
fit_2pl = fit_mirt(resp_matrix, model="2PL", item_names=item_names)
summary_2pl = pd.DataFrame({
"discrimination": fit_2pl.model.discrimination.round(3),
"difficulty": fit_2pl.model.difficulty.round(3),
}, index=item_names)
print(summary_2pl.to_string()) discrimination difficulty
MA1 1.073 -2.088
MA2 1.389 -0.243
MA3 2.049 -0.099
MA4 2.085 0.196
MB1 2.377 -0.338
MB2 1.932 -0.338
MB3 2.845 0.268
MB4 2.989 0.254
MC1 1.988 -0.778
MC2 2.097 0.010
MC3 1.951 -0.464
MC4 2.304 -0.157
MD1 2.428 -0.451
MD2 2.090 -0.699
MD3 2.459 -0.262
MD4 2.022 -0.300
ME1 2.154 -0.529
ME2 2.145 0.217
MF1 2.147 -0.197
MG1 4.383 0.096
MG2 4.998 0.207
MG3 4.578 0.071
MG4 5.000 0.113
MH1 1.026 -0.031
MH2 1.477 0.369
MH3 1.361 0.209
MH4 1.348 0.536
MI1 0.828 0.855
MI2 1.290 0.089
MI3 1.438 1.055Fit the 3PL model
The 3PL adds a lower asymptote (c, the “guessing”) parameter per item. This is appropriate when chance-level correct responding is plausible (e.g., multiple-choice exams).
fit_3pl = fit_mirt(resp_matrix, model="3PL", item_names=item_names)
summary_3pl = pd.DataFrame({
"discrimination": fit_3pl.model.discrimination.round(3),
"difficulty": fit_3pl.model.difficulty.round(3),
"guessing": fit_3pl.model.guessing.round(3),
}, index=item_names)
print(summary_3pl.to_string()) discrimination difficulty guessing
MA1 1.168 -1.149 0.500
MA2 1.133 -0.210 0.000
MA3 1.521 -0.037 0.000
MA4 1.558 0.360 0.000
MB1 1.785 -0.358 0.000
MB2 1.436 -0.358 0.000
MB3 2.069 0.470 0.000
MB4 2.190 0.450 0.000
MC1 1.510 -0.932 0.000
MC2 1.590 0.110 0.000
MC3 1.521 -0.508 0.000
MC4 1.731 -0.115 0.000
MD1 1.904 -0.495 0.000
MD2 1.710 -0.787 0.000
MD3 1.860 -0.254 0.000
MD4 1.557 -0.299 0.000
ME1 1.590 -0.618 0.000
ME2 1.684 0.380 0.000
MF1 1.567 -0.172 0.000
MG1 2.793 0.256 0.006
MG2 2.987 0.430 0.000
MG3 3.275 0.237 0.024
MG4 3.022 0.282 0.000
MH1 3.176 0.743 0.357
MH2 2.869 0.804 0.206
MH3 2.531 0.719 0.236
MH4 2.404 0.905 0.171
MI1 2.592 1.226 0.247
MI2 1.123 0.395 0.082
MI3 2.586 1.255 0.103Plot item characteristic curves (ICCs)
Visualizing ICCs gives an intuitive view of how each item functions. Here we compare a selection of items across the 1PL and 2PL.
theta_range = np.linspace(-4, 4, 200)
def icc_1pl(theta, b):
return 1 / (1 + np.exp(-(theta - b)))
def icc_2pl(theta, a, b):
return 1 / (1 + np.exp(-a * (theta - b)))
difficulty_1pl = fit_1pl.model.difficulty
discrimination_2pl = fit_2pl.model.discrimination
difficulty_2pl = fit_2pl.model.difficulty
fig, axes = plt.subplots(1, 2, figsize=(12, 5), sharey=True)
for idx, name in zip(range(5), item_names[:5]):
axes[0].plot(theta_range, icc_1pl(theta_range, difficulty_1pl[idx]), label=name)
axes[1].plot(theta_range, icc_2pl(theta_range, discrimination_2pl[idx], difficulty_2pl[idx]), label=name)
for ax, title in zip(axes, ["1PL (Rasch)", "2PL"]):
ax.set_title(title)
ax.set_xlabel("Ability (θ)")
ax.set_ylabel("P(correct)")
ax.axhline(0.5, color="grey", linestyle="--", linewidth=0.8)
ax.legend(fontsize=8)
ax.set_ylim(0, 1)
fig.suptitle("Item Characteristic Curves", fontsize=14)
plt.tight_layout()
plt.show()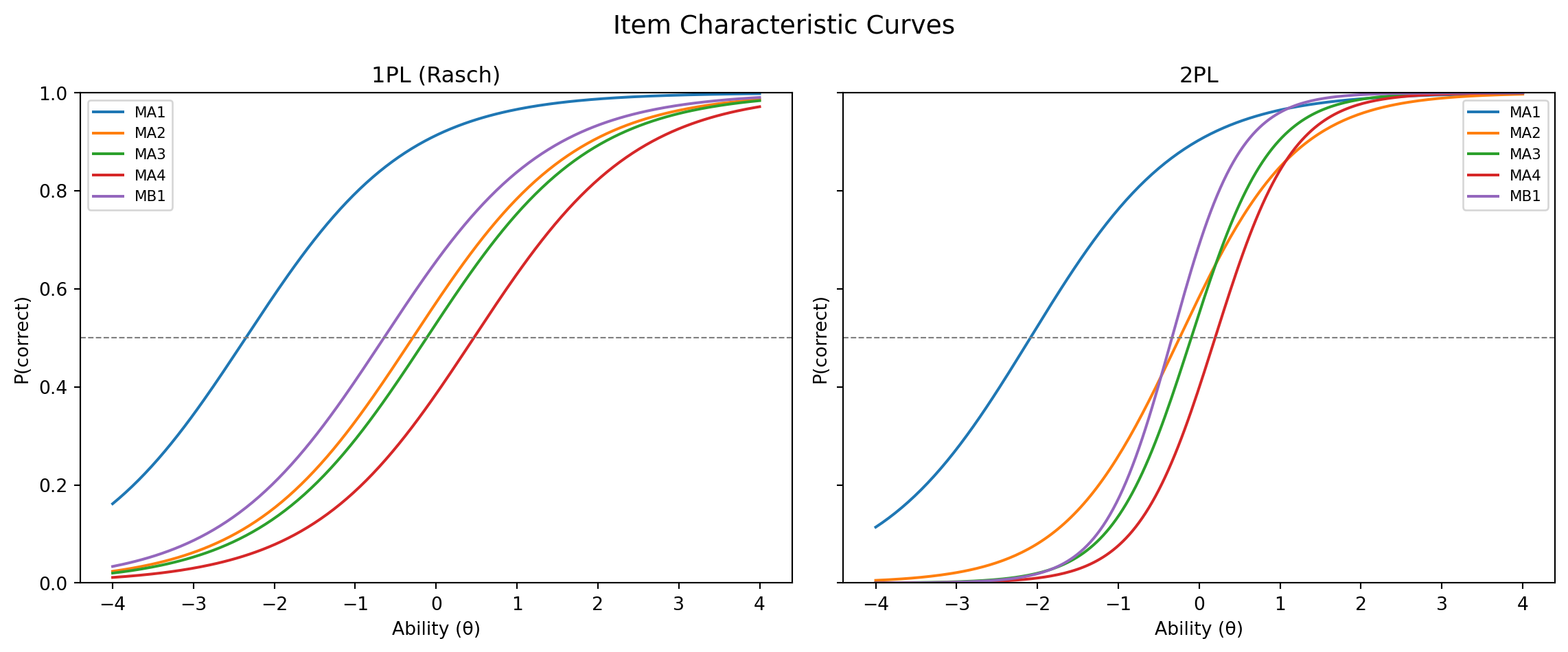
Part 2: Polytomous IRT (Graded Response Model)
The Graded Response Model (GRM) is appropriate for ordered polytomous items (e.g., Likert-scale survey responses). We use girth for the GRM, which has a stable MML implementation for polytomous models.
Fetch a polytomous dataset
df_poly = irw.fetch("5personalityfactors")
print(df_poly.head())
print(f"\nUnique response categories: {sorted(df_poly['resp'].dropna().unique())}")Warning: Setting the REDIVIS_API_TOKEN for interactive sessions is deprecated and highly discouraged.
Please delete the token on Redivis and remove it from your code, and follow the authentication prompts here instead.
This environment variable should only ever be set in a non-interactive environment, such as in an automated script or service.
Warning: Setting the REDIVIS_API_TOKEN for interactive sessions is deprecated and highly discouraged.
Please delete the token on Redivis and remove it from your code, and follow the authentication prompts here instead.
This environment variable should only ever be set in a non-interactive environment, such as in an automated script or service.
id item resp age
0 15111 10_agreeableness 1.0 18
1 21348 10_agreeableness 1.0 18
2 22571 10_agreeableness 1.0 18
3 30530 10_agreeableness 1.0 18
4 31443 10_agreeableness 1.0 18
Unique response categories: [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, nan]Prepare the response matrix
girth expects a (n_items, n_persons) integer array with categories coded starting from 0 and missing values encoded as INVALID_RESPONSE (girth’s sentinel, -99999). We shift the responses so the lowest observed category becomes 0, round any values produced by duplicate-response averaging, then transpose.
resp_wide_poly = irw.long2resp(df_poly)
resp_wide_poly = resp_wide_poly.drop(columns="id", errors="ignore")
# Convert to numeric; shift so minimum category = 0
resp_arr_poly = resp_wide_poly.apply(pd.to_numeric, errors="coerce").to_numpy(dtype=float, na_value=np.nan)
min_resp = int(np.nanmin(resp_arr_poly))
resp_arr_poly = resp_arr_poly - min_resp
n_categories = int(np.nanmax(resp_arr_poly)) + 1
print(f"Persons: {resp_arr_poly.shape[0]}, Items: {resp_arr_poly.shape[1]}, Categories: {n_categories}")
# Round averaged duplicates, encode missing as INVALID_RESPONSE, transpose to (items × persons)
resp_matrix_poly = np.where(np.isnan(resp_arr_poly),
INVALID_RESPONSE,
np.round(resp_arr_poly)).astype(int).T
resp_matrix_poly = tag_missing_data(resp_matrix_poly, list(range(n_categories)))Found 1260 responses across 1260 unique id-item pairs (0.2% of total).
Average responses per pair: 1.0.
Aggregating responses based on agg_method='mean'.
Persons: 8936, Items: 70, Categories: 7Fit the Graded Response Model
grm_results = grm_mml(resp_matrix_poly)
discrimination_grm = grm_results["Discrimination"]
thresholds_grm = grm_results["Difficulty"] # shape: (n_items, n_categories - 1)
# Display results for first 10 items
item_names_poly = resp_wide_poly.columns.tolist()
for i in range(min(10, len(item_names_poly))):
thresh_str = ", ".join([f"{t:.2f}" for t in thresholds_grm[i]])
print(
f"{item_names_poly[i]:30s} "
f"a = {discrimination_grm[i]:.3f} "
f"b = [{thresh_str}]"
)Warning: invalid value encountered in log
Warning: divide by zero encountered in log
10_agreeableness a = 0.769 b = [-5.95, -3.71, -1.70, -0.22, 1.28, 4.12]
10_conscientiousness a = 0.818 b = [-3.52, -1.11, 0.44, 1.68, 3.60, 5.91]
10_extraversion a = 1.044 b = [-4.44, -2.79, -1.31, -0.29, 0.90, 2.80]
10_neuroticism a = 0.778 b = [-4.01, -1.31, 0.24, 1.52, 3.55, 5.92]
10_openness a = 1.044 b = [-5.89, -3.18, -1.36, 0.17, 1.99, 4.41]
11_agreeableness a = 1.122 b = [-4.49, -2.78, -1.65, -0.66, 0.84, 2.88]
11_conscientiousness a = 1.152 b = [-4.91, -2.97, -1.57, -0.48, 0.92, 2.59]
11_extraversion a = 1.476 b = [-3.38, -2.13, -1.28, -0.52, 0.69, 2.26]
11_neuroticism a = 0.602 b = [-5.84, -2.51, -0.56, 1.10, 3.23, 5.90]
11_openness a = 1.024 b = [-5.94, -3.66, -1.94, -0.50, 1.19, 3.08]Plot category response curves (CRCs)
Category response curves show the probability of each response category as a function of ability. We plot CRCs for a single example item.
from scipy.special import expit
def grm_crc(theta, a, thresholds):
"""
GRM category response curves.
P(X=k|θ) = P*(X≥k|θ) − P*(X≥k+1|θ), where P*(X≥k|θ) = logistic(a*(θ−b_k)).
"""
cum_probs = np.array([expit(a * (t - theta)) for t in thresholds])
cum_probs = np.vstack([np.ones_like(theta), 1 - cum_probs, np.zeros_like(theta)])
return -np.diff(cum_probs, axis=0)
item_idx = 0
item_name = item_names_poly[item_idx]
a_item = discrimination_grm[item_idx]
b_item = thresholds_grm[item_idx]
crc = grm_crc(theta_range, a_item, b_item)
fig, ax = plt.subplots(figsize=(8, 5))
for k in range(crc.shape[0]):
ax.plot(theta_range, crc[k], label=f"Category {k + 1}")
ax.set_title(f"GRM Category Response Curves\n{item_name}")
ax.set_xlabel("Trait level (θ)")
ax.set_ylabel("Response probability")
ax.legend()
ax.set_ylim(0, 1)
plt.tight_layout()
plt.show()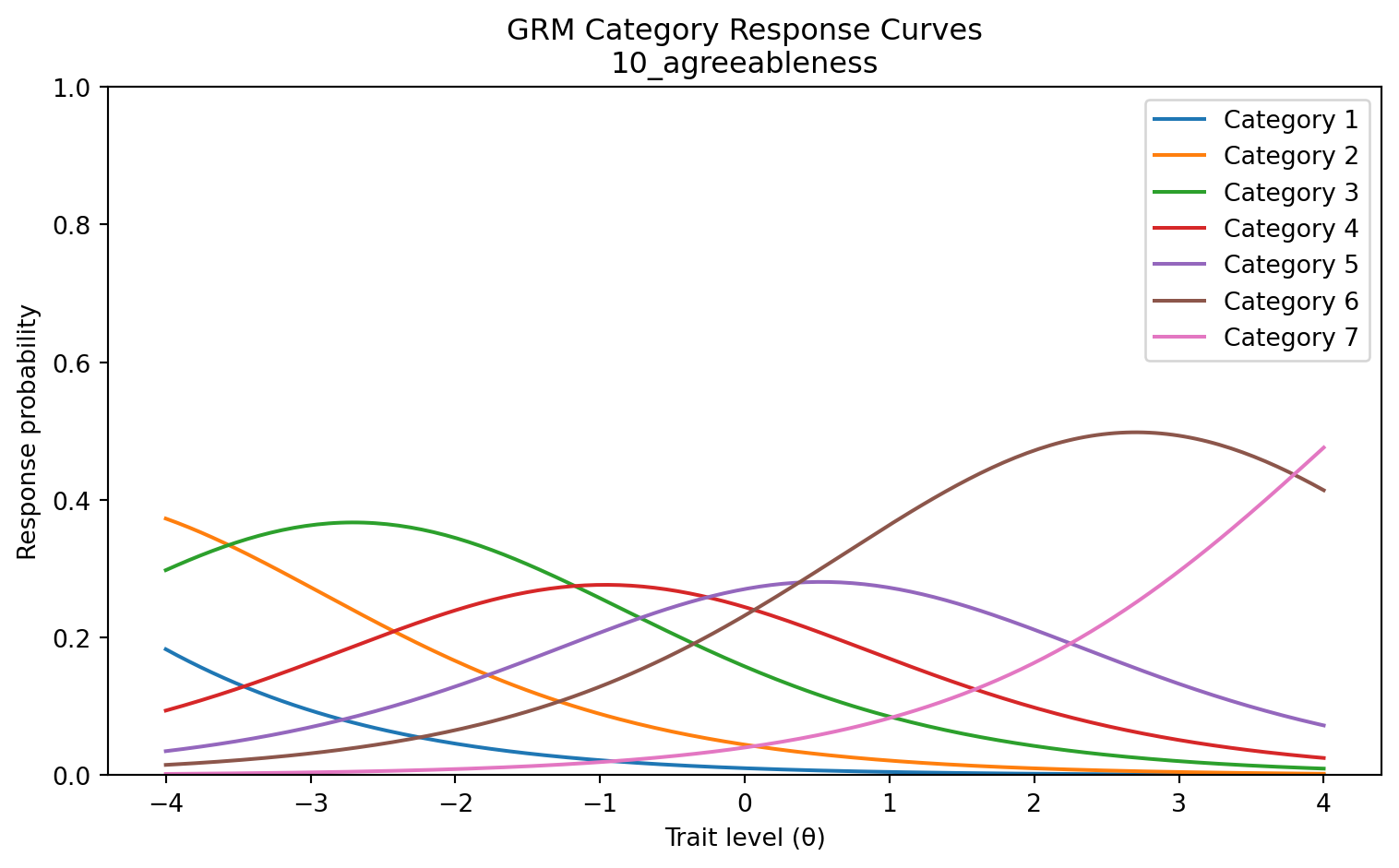
Summary
The table below recaps the models covered and when to use each one.
| Model | Package | Response type | Parameters per item | Use when |
|---|---|---|---|---|
| 1PL (Rasch) | mirt |
Dichotomous | difficulty b |
Equal discrimination is theoretically warranted |
| 2PL | mirt |
Dichotomous | a, b |
Items vary in how well they discriminate |
| 3PL | mirt |
Dichotomous | a, b, c |
Multiple-choice; guessing is plausible |
| GRM | girth |
Polytomous (ordered) | a, b₁…bₖ₋₁ |
Likert or partial-credit items |
For a broader exploration of 2PL discrimination parameters across many IRW datasets, see the 2PL Across Datasets vignette. To compare model fit between the 1PL and 2PL using cross-validated predictions, see the IMV vignette.